
音楽資料目録のヒント:テーマ 4:人口統計グループ用語 を 目録にとりいれる
人口統計グループ用語 (=LCDGT) は, 固有の統制語彙です.
実体の属性を示す語彙のひとつであり,
必要に応じて
書誌レコードで創作者,寄稿者,資源の利用対象者の特性を記述するために使われます.
個人名や著作を記述する典拠レコードでも使用されます.
一般的な人口の[一部/集合]として定義され,
年齢,職業,民族的背景,病状などを表します.
例えば,
Spaniards = スペイン人
Fire fighters = 消防士
College students = 大学生
Gays = ゲイ
Hearing impaired = 聴覚障害者
LCがRDA使用を前提に開発し,
2015年から運用しているLCDGTに含まれる用語は,
文献的根拠, 利用者や組織的な要請に基づいており,
音楽資料を多く扱う Toccata MARC (※1) も適用しています.
(※1) Toccata MARC: LCのRDA適用と同時期にRDAの段階的使用を始め,
日本語処理を付加したUNIMARCフォーマットにRDAによる書誌データを格納している
MARCは,
ひとつひとつの資料の特徴を分析し
一定の規則に基づいて探索しやすいようにした情報です.
特定の実体を発見するには, 他と区別しなくてはなりません.
人口統計グループ用語は, その手掛かりとなります.
例えば, ひとりの個人は
複数の人口統計グループに属している可能性があります.
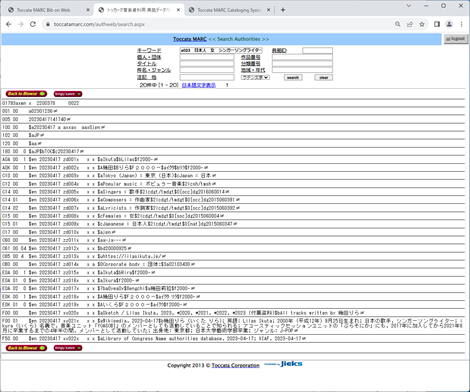
■ 例: 人口統計グループ用語 典拠データへの登録 ■
ある日本人の女性シンガーソングライターについて,
Toccata 典拠データの登録内容
フィールド: C14 (職業)
※Singers = 歌手
※Composers = 作曲家
※Lyricists = 作詞家
フィールド: C15 (個人または団体のその他の属性)
※Japanese = 日本人
※Females = 女
[参照] Toccata MARC 典拠データ クイックレファレンス
(Toccata MARC 典拠レコードの内容識別子をリストアップしたもの)
https://toccata.co.jp/wp-content/uploads/2024/04/bib_quick_ref.pdf
膨大なデータから特定の 「ひとつ」 を発見する, という行為は
図書館目録に限ったことではありません.
人口統計グループの考え方/機能は
目録の世界にとどまらず,
人口の管理をしている自治体,官公庁などで使われています.
[参考] 総務省統計局 「第七十二回日本統計年鑑 令和5年」
https://www.stat.go.jp/data/nenkan/index1.html
人口統計グループに限らず
目録について考え, あらゆる角度で判断するときに必要な “視点” のひとつに,
「マイノリティに着目する」 ことが挙げられます.
~それは繊細な気付きが求められる作業といえます.
カタロギング以外のフィールドでも
様々な経験を積み, 物事に触れ, 自身の発想を豊かにすることは
カタロガーに求められる資質のひとつかもしれません.
今回ご紹介した内容をさらに詳しく知りたい方は,
当社より発売中の 「議会図書館 人口統計グループ用語」 をご覧ください.
2023年6月2日付 図書館情報部より全国送信mail [CDご選定用データ, 最新情報] より
一部抜粋,加工修正しました